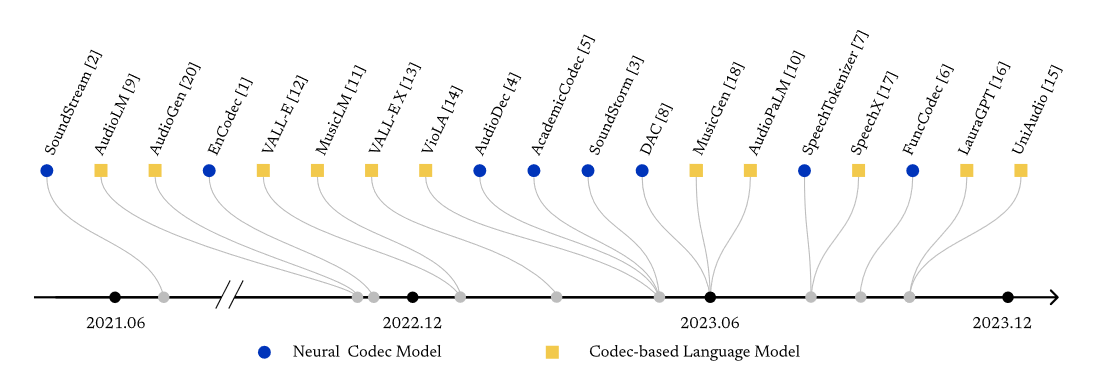
两则综述
1. Towards audio language modeling - an overview 缘起压缩传数据,后来这种离散化连续语音音频很适用于语音语言模型。 SoundStream为万恶之源。 Ⅰ. SoundStream (1) 模型 编码器——将raw audio映射到嵌入序列 量化器——用一组有限码本的矢量和代替每个嵌入 解码器——从量化嵌入产生有损的重建 ...
1. Towards audio language modeling - an overview 缘起压缩传数据,后来这种离散化连续语音音频很适用于语音语言模型。 SoundStream为万恶之源。 Ⅰ. SoundStream (1) 模型 编码器——将raw audio映射到嵌入序列 量化器——用一组有限码本的矢量和代替每个嵌入 解码器——从量化嵌入产生有损的重建 ...
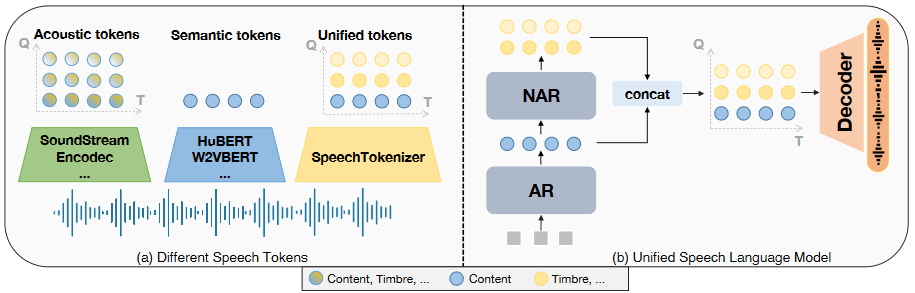
0. 摘要 专门设计的、结合两方面的新模型。新的评估测试集SLMTokBench benchmark。 1. 引言 LLM的卓越表现促进了语音语言模型的发展。在多种语音处理任务中都使用到了离散语音表示。如下图所示。 语义表征(semantic tokens)通常是自监督的预训练模型,训练目标是掩码语言建模,通过特定中间层对表征进行k-means聚类,表征是一维结构的序列。声学表征(acoustic tokens)通常是神经音频编解码器模型,训练目标是音频重构,通过RVQ(residual vector quantization)进行离散化,表征是由时间步长和量化器两个维度组成的矩阵。 ...

一. EnCodec 1. 模型任务 EnCodec是在SoundStream模型的基础上提出的,用于实现音频数据的高效压缩。其被提出是为了解决音频数据的实时传输,因为要保证数据传输的实时性,所以需要对音频数据进行压缩,同时也要保证被压缩的质量。该工作就是利用神经网络来解决压缩与恢复工作。 ...